





Nowadays, dealing with datasets of terabytes or petabytes is a reality. Dataset of so much volume is termed as Big Data. Big Data cannot be processed by traditional applications used for data processing. The main challenges are in capturing, storing, querying, transferring and visualization of data. The demand to handle Big Data creates the need for tools that can process Big Data in purposeful way and one such tool is Apache Hadoop.
Apache Hadoop is an open source software framework used to process very large data set on distributed storage. Hadoop consists mainly of two parts for storage- Hadoop Distributed File System (HDFS) and MapReduce for Processing. Hadoop works by splitting up files into large blocks and then distributes the nodes along clusters. HDFS allows Hadoop to work with files up to petabyte storage. With the help of MapReduce Hadoop can take large amount of data for processing and then break it into small components that run in parallel over distributed computers.
Hadoop works on Non-Relation data sets. By the virtue of processing for non-structural, massively parallel processing, easy using and many more advantages, it becomes a mainstream technology. Google in 2004 proposed a model, i.e., MapReduce used for parallel processing and generating big data, which is a linear, scalable programming model. Hadoop becomes the first choice of users as it is a open source and easy to use. Many companies like Google, Facebook, Yahoo, etc manage their large amount of data by using hadoop as it processes the data efficiently.
Hadoop consists mainly of two parts: MapReduce for Processing and Storage Hadoop Distributed File System (HDFS). Hadoop works by splitting up files into large blocks and then distributes the nodes along clusters. HDFS allows hadoop to work with files up to petabyte storage. With the help of MapReduce, hadoop can take large amount of data for processing and then can break it into small components that run in parallel over distributed computers. Hadoop consists of two core parts, HDFS(Hadoop File System) and MapReduce ,the focus is on these two core parts. HDFS is based on distributed file system design. It is designed by using low cost hardware and highly fault tolerant. It stores large amount of data and provides easy access. HDFS stores large amount of data, by storing data on multiple machines. It stores file in redundant way so that in case of failure also, there is no data loss. It provides applications parallel processing capability. HDFS is a client-server architecture which comprises of NameNodes and many DataNodes. The NameNode is used to store the metadata for the NameNode. NameNodes keep track of the state of the DataNodes.
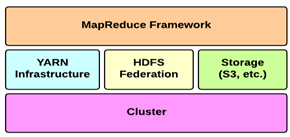
Fig1: Apache Hadoop architecture
MapReduce is a framework by which applications can be written to process large amount of data in parallel. Hadoop MapReduce, is the very popular open source implementation of the MapReduce framework proposed by Google. It is based on Java .It has two main tasks- Mapping and Reduction. The main work of map is to process the input data and the input is in the form of directory or file which is stored in HDFS. The input file is processed by map or mapper, line- by- line and then, creates small chunks of these files. Reduce stage is combination of shuffle and reduce. Its work is to process data coming from mapper and creates the new set of output and then stores them in HDFS again. The Hadoop MapReduce framework uses a distributed file system to read and write its data. Generally, Hadoop MapReduce uses the Hadoop Distributed File System (HDFS) and it is the open source counterpart of the Google File System .The input-output performance of hadoop depends mainly on its file system (HDFS).








 & their solution")

 – Motivational video 2017")


{kind=link}